前言
java学习之路—–>XML学习
内容
XML学习
XML引入
HTML: 负责网页的结构
CSS: 负责网页的样式(美观)
Javascript: 负责在浏览器端与用户进行交互。
HTML与XML区别
HTML负责静态的网页制作的语言
HTML语言特点:
1)由标签组成。 <title> <p> <hr/> <br/>
2)语法结构松散的 <p></p> <p> <P>
大小写不区分
结束标签和开始标签不一定匹配
XML是HTML中的自定义标签
XML作用
描述带关系的数据(软件配置文件)
web服务器(PC):
学生管理系统 -> 添加学生功能 -> 添加学生页面 ->
name=eric&email=eric@qq.com
前提: 网络(IP地址: oracle:255.43.12.54 端口:1521 )
java代码:使用ip(255.43.12.54)地址和端口(1521),连接oracle数据
库,保存学生数据。
把ip地址端口配置到xml文件:
host.xml
<host>
<ip>255.43.12.55</ip>
<port>1521</port>
</host>
数据库服务器(PC):
主服务器(255.43.12.54):Oracle数据库软件(负载)
副服务器(255.43.12.55):Oracle数据库软件
数据的载体(小型的”数据库”)
教师管理系统: 姓名 工龄+1 邮箱
发教师数据给财务管理系统:
String teacher = name=张三&email=zhangsan@qq.com&workag
e=2 字符串
(问题: 1)不好解析 2)不是规范)
teacher.xml
<teacher>
<name>张三</name>
<email>zhangsan@qq.com</email>
<workage>2</workage>
</teacher>
这种一种规范
财务管理系统:
姓名 工龄+1 邮箱
发奖金: 统计奖金。 工龄
发邮件功能:
邮箱 姓名 金额
方案一: 在财务管理系统中维护了一套教师信息。
每年 : 工龄增加 维护了两个系统的信息。
方案二: 教师信息只在教学管理系统中维护。
XML语法
xml文件以xml后缀名结尾。
xml文件需要使用xml解析器去解析。浏览器内置了xml解析器。
标签:
语法:
<student> 开始标签
student 标签内容
</student> 结束标签
<student />空标签
xml严格区分大小写
xml标签一定要正确配对
xml标签名中间不能加空格
xml标签名不能以数字开头
xml根标签只能有一个
属性:
<student name="eric"> student </student>
xml属性值一定要以引号包含,不能省略,也不能单双引号混用
一个标签内可以有多个属性,但是不能重复
注释:
<!-- xml注释 -->
文档声明:
<?xml version="1.0" encoding="utf-8"?>
version 版本号默认1.0
encoding 解析xml文件时查询的码表(解码过程时查询的码表)
注意:
1)如果在ecplise工具中开发xml文件,保存xml文件时自动按照文档声明的enco
ding来保存文件。
2)如果用记事本工具修改xml文件,注意保存xml文件按照文档声明的encoding的
码表来保存。
XML转义字符:
在xml中内置了一些特殊字符,这些特殊字符不能直接被浏览器原样输出。
如果希望把这些特殊字符按照原样输出到浏览器,对这些特殊字符进行转义。
转义之后的字符就叫转义字节。
特殊字符 转义字符
< <
> >
" "
& &
空格 &nsbp;
CDATA块:
作用: 可以让一些需要进行包含特殊字符的内容统一进行原样输出。
<![CDATA[
<html>
</html>
]]>
处理指令:
作用: 告诉xml解析如果解析xml文档
案例:
<?xml-stylesheet type="text/css" href="1.css"?> 告诉xml解析该xml
文档引用了哪个css文件
需要提前xml内容可以使用xml-stylesheet指令指令
XML解析
xml文件除了给开发者看,更多的情况使用程序读取xml文件的内容。这叫做xml解析
XML解析方式
DOM解析
SAX解析
XML解析工具
DOM解析:
JAXP
JDOM工具
Dom4J工具
三大框框使用
SAX解析:
SAX解析工具(官方)
什么是DOM解析
xml解析器一次性把整个xml文档加载进内存,然后在内存中构建一颗Document的
对象树,通过Document对象,得到树上的节点对象,通过节点对象访问(操作)到xml文
档的内容
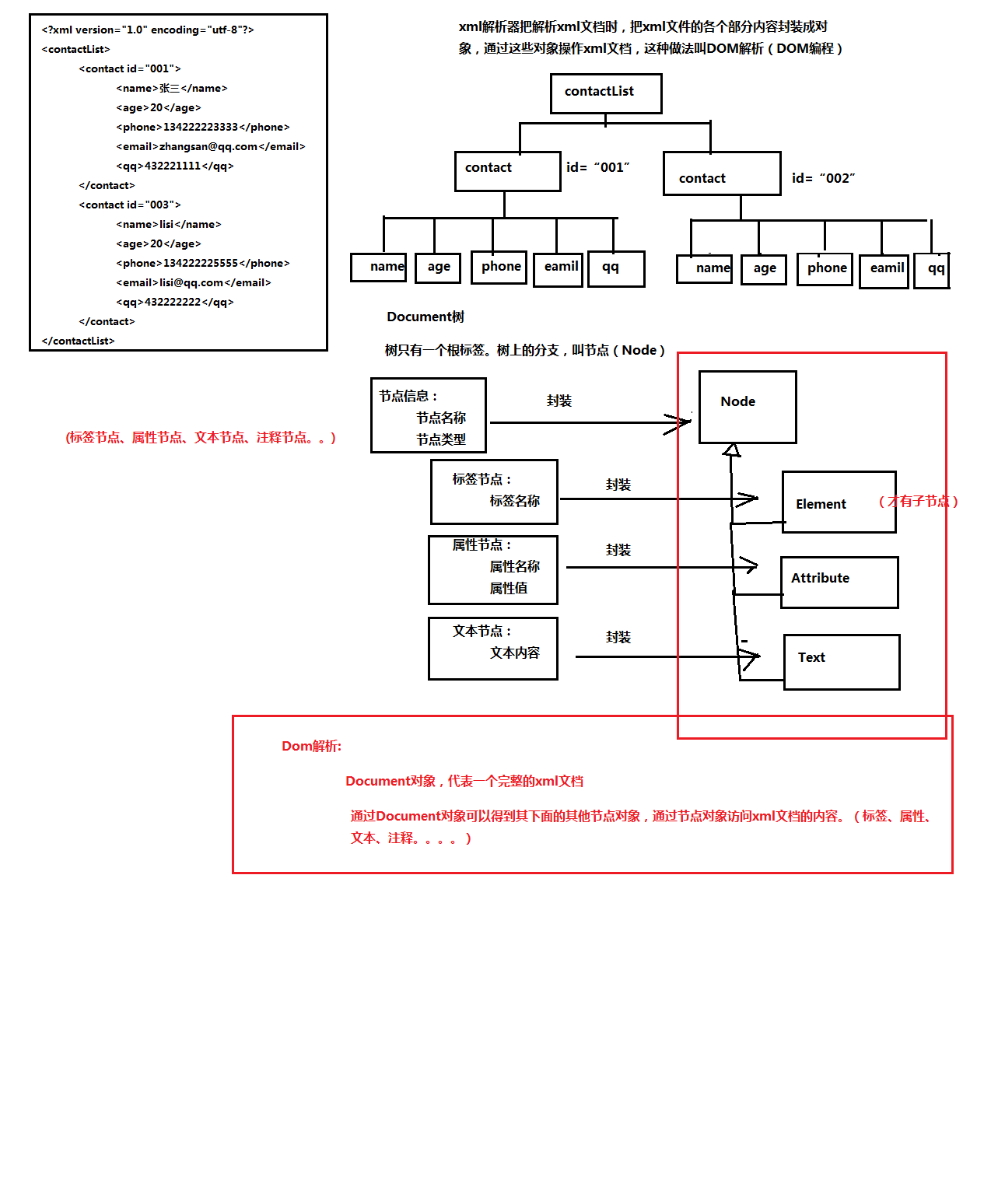
DOM解析
Dom4J工具
非官方,不在jdk
使用步骤:
1)导入dom4j的核心包。 dom4j-1.6.1.jar
2)编写Dom4j读取xml文件代码
Dom4J读取xml文件
节点:
iterator Element.nodeIterator;//获取当前标签节点下的所有子节点
标签:
Element Document.getRootElement();//获取xml文档的根标签
Element ELement.element("标签名");//指定名称的第一个子标签
Iterator<Element> Element.elementIterator("标签名");// 指定名称的
所有子标签
List<Element> Element.elements(); //获取所有子标签
属性:
String Element.attributeValue("属性名") //获取指定名称的属性值
Attribute Element.attribute("属性名");//获取指定名称的属性对象
Attribute.getName() //获取属性名称
Attibute.getValue() //获取属性值
List<Attribute> Element.attributes(); //获取所有属性对象
Iterator<Attribute> Element.attibuteIterator(); //获取所有属
性对象
文本:
Element.getText(); //获取当前标签的文本
Element.elementText("标签名") //获取当前标签的指定名称的子标签的文本
内容
Dom4J修改xml文件
写出内容到xml文档
XMLWrite write = new XMLWriter(OutputStream,OutputForamt);
write.write(Document);
修改xml文档的api
增加:
DocumentHelper.createDocument() 增加文档
addElement("名称") 增加标签
addAttribute("名称","内容")
修改:
Attribute.setValue("值") 修改属性值
Element.addAttribute("同名的属性名","值") 修改同名的属性值
Element.setText("内容") 修改文本内容
删除:
Element.detach() 删除标签
Attribute.detach()删除属性
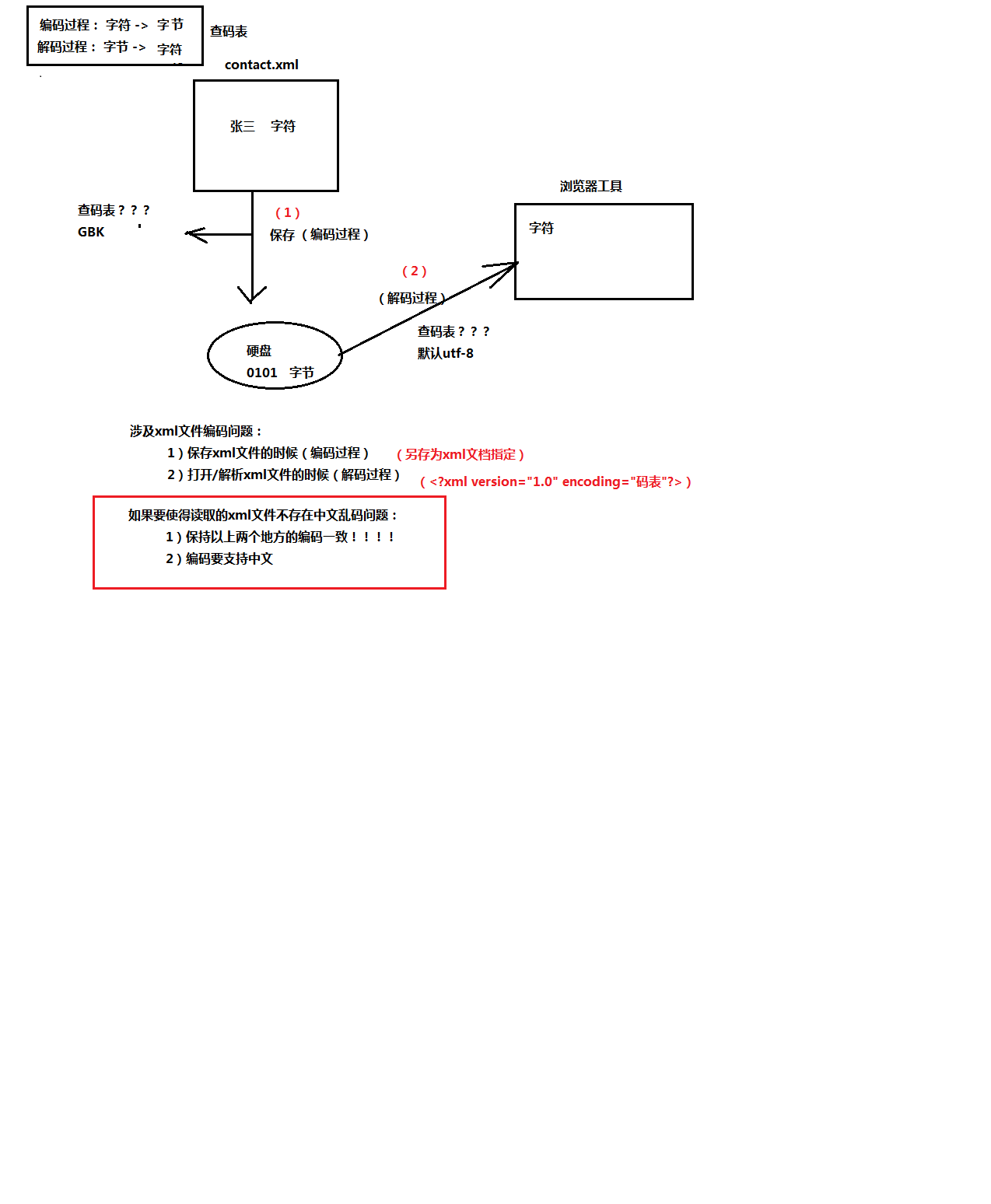
XML乱码问题
xPath技术
引入
当dom4j查询比较深的层次结构的节点比较麻烦
作用
快速获取所需的节点对象
运用
1) 导入xPath支持包.
2) 使用方法
List<Node> selectNodes("xPath表达式"); 查找多个节点
Node selectSingleNode("xPath表达式"); 查找一个节点对象
xPath语法
/ 绝对路径 表示从xml的根位置开始或者子元素(一个层次结构)
// 相对路径 表示不分任何层次结构的选择元素
* 通配符 表示所有元素
[] 定域 表示选择什么条件下的元素
@ 属性 表示选取属性节点
SAX解析
加载一点,读取一点,处理一点,对内存要求低。
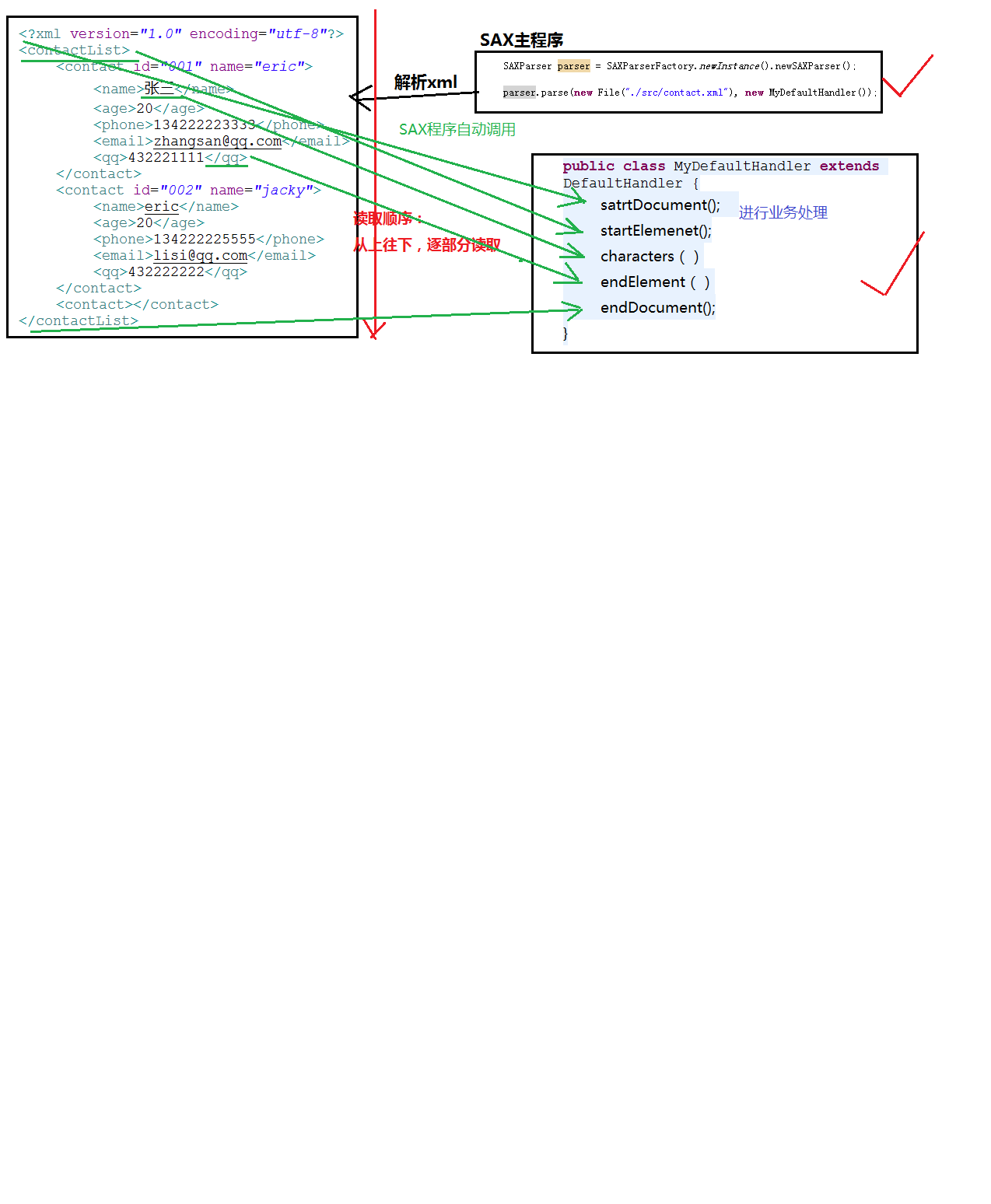
SAX解析
SAX解析工具
Sun公司提供,内置在Jdk中。 org.xml.sax
核心Api
SaxParser类 用于读取和解析xml文件
parse(File?f, DefaultHandler?dh)放法,解析xml文件
参数一:File 表示读取的xml文件路径
参数二:DefaultHandler Sax事件处理程序,使用DefaultHandler的子类
例如:
1.创建SAXParser对象
SAXParser parser=SAXParserFactory.newInstance().newSAXParse
r();
2.调用parse方法
parser.parse(new File("./src/contact.xml"), new MyDefaultHan
dler());
[一个类继承class 类名(extends DefaultHandler) 在调用是创建传
进去
DefaultHandler类的APi
void starDocument() 在读到文档开始时调用
void EndDocument() 在读到文档结束时调用
void startElement(String uri, String localName, String qName, At
tributes attributes) :读到开始标签时调用
void endElement(String uri, String localName, String qName)
:读到结束标签时调用
void characters(char[] ch, int start, int length) : 读到文本内容
时调用
DOM解析与SAX解析区别
DOM解析
原理: 一次性加载xml文档,不适合大容量的文件读取
DOM解析可以任意进行增删改成
DOM解析任意读取任何位置的数据,甚至往回读
DOM解析面向对象的编程方法(Node,Element,Attribute),Java开发者编码比较简
单。
SAX解析
原理: 加载一点,读取一点,处理一点。适合大容量文件的读取
SAX解析只能读取
SAX解析只能从上往下,按顺序读取,不能往回读
SAX解析基于事件的编程方法。java开发编码相对复杂。
XML约束
只要能看懂约束内容,根据约束内容写出符合规则的xml文件
引入
xml语法:规范的xml文件的基本编写规则.(由w3c组织规定的)
xml约束:规范xml文件数据内容格式的编写规则.(开发者自己定义)
XML约束技术
DTD约束:语法简单,功能简单
Schema约束:语法复杂,功能相对强大(名称空间)
DTD约束
1)导入方式
内部导入
<!DOCTYPE note [
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
外部导入
本地系统导入
<!DOCTYPE note SYSTEM "note.dtd">
公共的外部导入
<!DOCTYPE 根元素 PUBLIC "网络地址.dtd">
2)DTD语法
约束标签
<!ELEMENT 元素名称 类别> 或 <!ELEMENT 元素名称 (元素内容)>
类别:
EMPTY 空标签 表示元素一定是空
#PCDATA 普通字符串 表示元素的内容一定是普通字符串(不能含有子标
签)
ANY 任何类型 表示元素的内容是可以任意内容(包括子标签)
元素内容:
顺序问题
<!ELEMENT 元素名称 (子元素名称 1,子元素名称 2,.....)>:
按顺序出现子标签
次数问题:
标签 : 必须且只出现1次。
标签+ : 至少出现1次
标签* : 0或n次。
标签? : 0 或1次。
约束属性
<!ATTLIST 元素名称 属性名称 属性类型 默认值>
默认值:
#REQUIRED 属性值是必需的
#IMPLIED 属性不是必需的
#FIXED value 属性不是必须的,但属性值是固定的
属性类型:控制属性值的
CDATA :表示普通字符串
(en1|en2|..): 表示一定是任选其中的一个值
ID:表示在一个xml文档中该属性值必须唯一。值不能以数字开头
Schema约束
名称空间:告诉xml文档的哪个元素被哪个schema文档约束。 在一个xml文档中,不同
的标签可以受到不同的schema文档的约束。
1)一个名称空间受到schema文档约束的情况
2)多个名称空间受到多个schema文档约束的情况
3)默认名称空间的情况
4)没有名称空间的情况

Schema约束
版权声明:本文为博主原创文章,转载请注明出处KidSea

